DataOps Components
“If I have seen a little further it is by standing on the shoulders of Giants.”
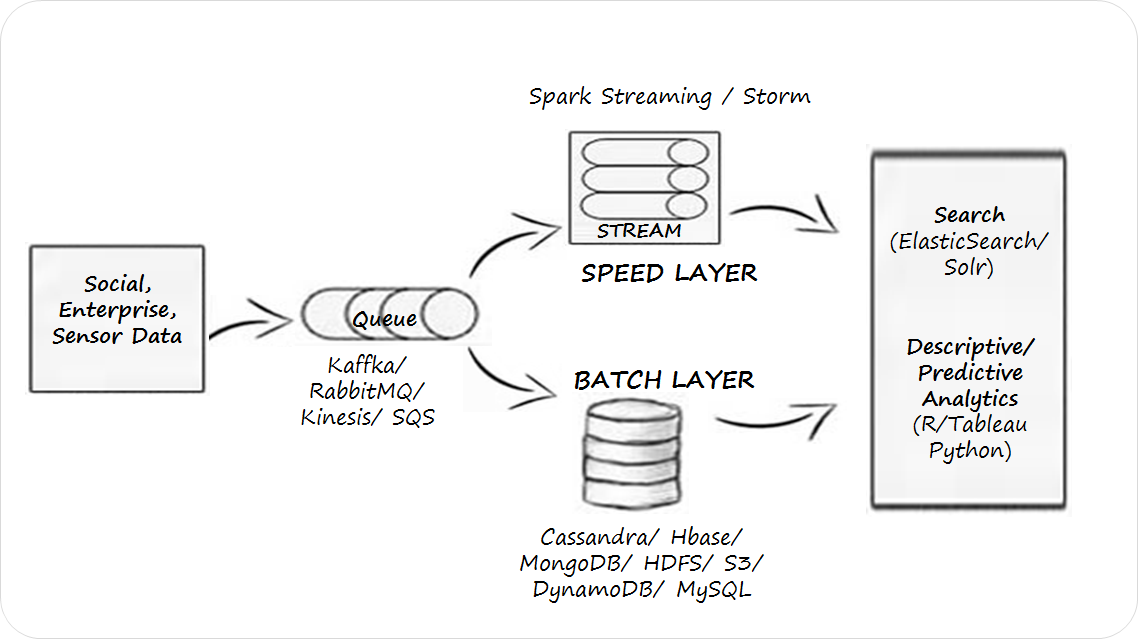
BigStream
A modern data platform needs to be flexible to handle various workloads corresponding to the diverse business objectives, be extensible to support existing and emerging data technologies, and to some extent be future-proof.
Our BigStream framework – Serendio’s implementation of the Lambda Architecture, was designed to accelerate your big data development.
Key Features:
- Support for Streaming/Batch data, structured/unstructured data, and a large library of pre-built Social and Enterprise Data Connectors.
- An extensible set of Data Transformation and Processing functions including Text Analytics
- Visual designer to construct data processing pipelines with minimal programming.
- Cloud enabled, Big Data design patterns with production deployment in Fintech, Industrial Internet, Education, Insurance, and Social Marketing.
- Kafka/RabbitMQ/SQS for Queuing
- Storm/Spark Streaming/Kinesis for stream computing
- Cassandra/MongoDB/HBase/HDFS/DynamoDB/S3/MySQL for persistence
- ElasticSearch/Solr for full text search
DisKoveror
DisKoveror is a Text Analytics framework developed by Serendio. Built on top of other open source packages, DisKoveror provides a flexible and extensible way to extract Entities, Topics, Categories, Sentiments, and Keywords from unstructured text.
The key advantage of DisKoveror over the numerous open source options is it provides access to the best-of-breed components through a plug and play approach and a unified programming interface.
DisKoveror has also improved the output quality, in some cases, through Training sets, domain specific ontology, and folksonomy.
DisKoveror has been used to mine brand sentiments from social media, understand customer satisfaction from emails, extract topics from Tweets, compute social influence score, computer-assisted metadata and taxonomy creation, and much more.
DisKoveror Highlights
- Sentiment Analysis
- Topic Detection
- Named Entity Recognition
- Coreference Resolution
- Keyword Extraction
DisKoveror can be accessed through Java APIs or a RESTful interface Download

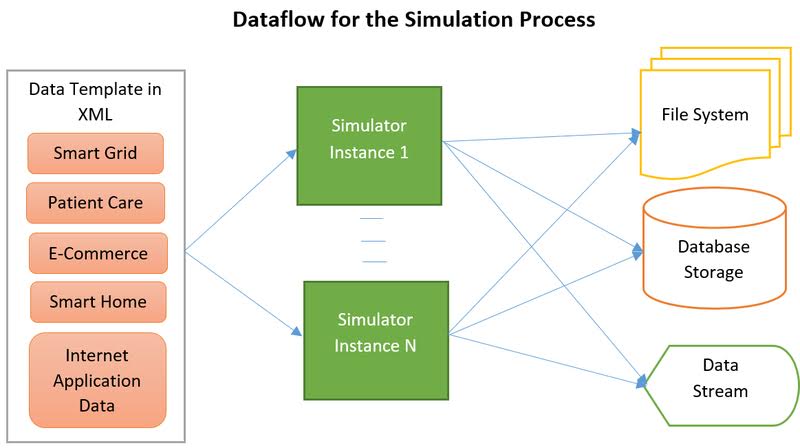
BigSim
BigSim is designed to provide flexibility and control in generating large data sets through templates and minimal coding. Users just need to provide the data specifications in an XML template defining the semantic type, range, volume, velocity, and shape. These simulated data sets could be used for capacity planning, what-if scenario testing, extrapolate small data sets with certain amount of randomness so as to simulate real-world data sets, fill in missing data in incomplete data sets and such.
- Designed to generate synthetic data to address hard-to-get data, dirty or missing data, and data for new use cases.
- Support for Streaming and Batch data generation through extensible data templates.
- Out-of-the-box templates for Wearables, Smart Homes, Retail, Manufacturing and more.
Data Wrangling
Data pre-processing is an important step in the data mining process. Data-gathering methods are often loosely controlled, resulting in out-of-range values, impossible data combinations (e.g., Sex: Male, Pregnant: Yes), and missing values.
Analyzing data that has not been carefully screened for such problems can produce misleading results. Thus, the representation and quality of data is first and foremost before running an analysis.
Highlights of PreMod, our Data Pre-Processing Package:
- Standardization – Standardize the raw feature vectors from the training data.
- Deviations – Calculate the deviation of a particular value from the average.
- Indicator Variables – Create Indicator variables representing the training data.
- Skewness – Compute the skewness of a sample within a training set.
- Kurtosis – Compute the kurtosis of a sample within a training set.
- Box-cox Transformation – Transform the training vectors using Box-cox.
- Poisson Transformation – Transform the training vectors using Poisson.
- Proportional Transformation – Transform the training vectors with Proportional transformation.
- Graphical Summary – Get a pictorial representation of the training data.
All the above functions are available in R and Python. Download